目录
本文是我因工作需要所写的针对 CockroachDB 的评测报告的删减版,去掉了一些与公司相关的信息。由于原本只是用作内部分享,只因觉得有分享价值才发布于博客,所以文中会残留一些同事之间交流的语气,请忽略便可。

CockroachDB 是一个可伸缩的、跨地域复制的、支持事务的、高可用、强一致性的分布式 SQL 数据库,隶属于 NewSQL 的概念,在 SQL 协议的支持上对标 PostgreSQL,完全用 Golang 实现。由于篇幅限制,这里不对 CockroachDB 的基本信息做介绍了,可查看 官网主页 的一些介绍做一些基础的了解。
由于官方文档没有中文翻译,目前也没有较权威的国内资料,所有一些专有名词均以英文原文形式保留。
一、分片设计
CockroachDB 将全量数据分割为一个个的块,称为 range(类比于 Mongo 的 chunk 或 Codis 的 slot),每个 Range 拥有多个(默认是三个)replica,每个 replica 会随机分配到不同的节点上进行存储。range 的分割、管理均为自动,无需关心,所以文档里没有具体介绍数据分块的技术内幕,目前只能确认:
- 同一个 range 不会包含不同数据表的数据,即每个有数据的数据表至少有一个专属 range;
- range 超过最大尺寸限制(可配置,默认 64 MB)时会分裂,(range 低于最小尺寸限制合并的特性尚未实现,目前只能配置但不会起作用);
- range 依照某个哈希索引进行分割,该索引与数据表的结构、主键、索引无关。
不同于 Mongo 或 Codis,Mongo 和 Codis 在设计上都是将节点进行预先编排,分为多个组(Mongo 称为 shard,Codis 称为 group),每个组有多个节点,互为主备,共同维护相同的数据。
而 CockroachDB 并没有这样设计,所有节点无需预先编排,均为“对等节点”,节点与节点之间没有绝对的主备关系,主备关系只可以就某个 range 来讨论,随着 range 的变动与迁移,主备关系也会随之变化。该设计比较类似 HDFS 的设计,但不同的是,HDFS 需要至少一个 NameNode 来管理数据在 DataNode 上的分布,而 CockroachDB 则是所有节点既参与管理也参与数据存储,是完全去中心化的。
下图展示了 MongoDB、Codis、CockroachDB 在分片设计的对比:
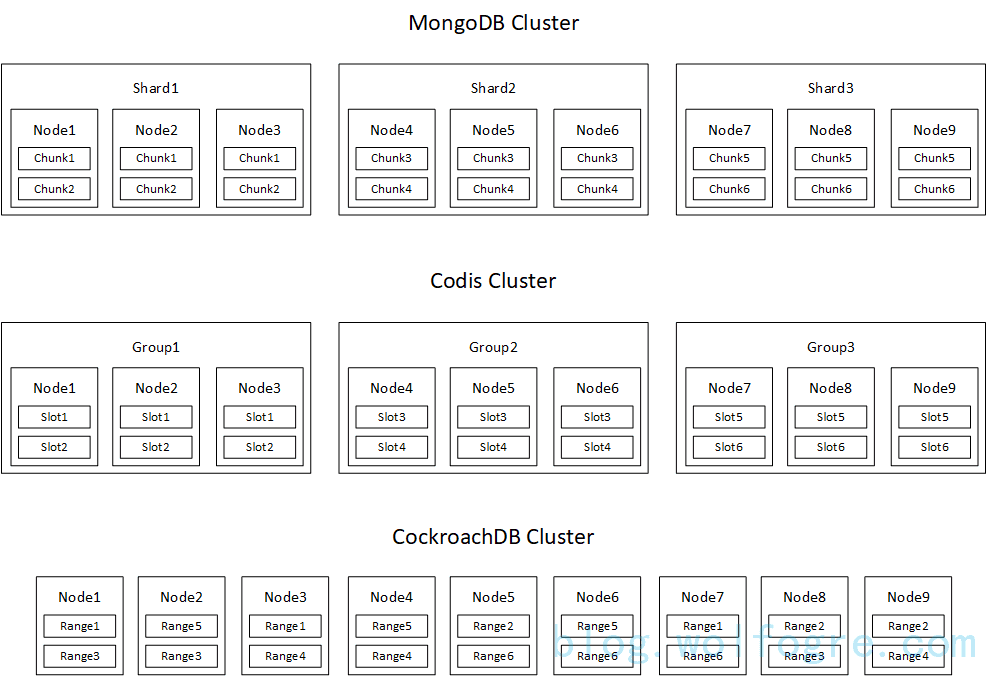
图中,可是说 MongoDB 的 Node1 和 Node2 是互为主备的,同属于 Shard1,且该关系将稳定存在(除非重新编排资源)。
但对于 CockroachDB,只能说能说 Node1 和 Node2 就 Range3 而言是互为主备的,因为它们各有一个 Range3 replica,但随着 Range3 replica 的迁移,主备关系可能会消失(比如 Node1 的 Range3 replica 迁到了别的 node 上)。
在部署和使用中,一般无需关心 range 的分割和分布。在工作过程中,属于同一个 range 的多个 replica,总会有一个且仅有一个是 range lease,会自动选举产生,作为领导者的角色,负责接收和协调针对该 range 读写操作。
选举办法基于 Raft 协议,所以 range lease 的产生需要大多数 replica 的投票。这就意味着,如果 replica 的数量是 2F + 1,那至少需要存活 F + 1 个 replica 才能保证 range lease 能够正确产生,进而保证该 range 的可用性。
默认一个 range 的 replica 数为 3,故,同一个 range 短时间内只能损失一个 replica。但这并不意味着整个集群不能接受超过 2 个 node 的同时宕机。如图中,假设 Node1 和 Node4 同时宕机,会造成 Range 1、3、4、5 各损失一个 replica,但仍可保持可用性。且一段时间后如果 Node1 和 Node4 仍无法恢复,缺失的 replica 会在其他 node 重建。详见下节。
二、单点故障
由于无需事先编排资源,CockroachDB 可以更有效的处理单节点故障。
具体来说,假设上图中的 Node1 的 Range1 replica 是 range lease,而 Range3 replica 不是 range lease。
当 Node1 宕机,Range1 将失去 range lease,但剩余 2 个 replica 仍可以选举出一个新的 range lease,顶替上去继续工作,而对于 Range3 而言则几乎不受影响。
此时 Node1 会被认为是处于 suspect 状态,即:“集群认为其暂时无法工作,但尚不确定是否是真的挂了还是网络波动,也不确定该节点能后及时恢复正常”。suspect 状态会持续一段时间,这个时间官方文档说是 10 分钟,但实际测试中似乎低于 10 分钟,原因不详,暂时认为是 10 分钟。在这 10 分钟内如果 Node1 恢复与集群的连接,则 Node1 可以继续原先的工作,整个集群恢复正常。
如果 Node1 在 10 分钟后仍没有恢复与集群的连接,则判定 Node1 进入 dead 状态,即:“集群认为其完全无法工作,短时间内也不能恢复正常”,Node1 便会被抛弃,它的工作会分摊给其他节点,Range1 和 Range3 缺少的 replica 将在其他节点上重新创建。之后整个集群也会恢复正常,但处理能力、容量有相应的减小。
一段时间后如果 Node1 又加入了集群,则被认为是新节点加入,重新为其安排工作。
三、灾备方案
需要提前说明,这里讨论的灾备方案无法应对只有两个机房(双活)的情景,因为无论是将两个机房建立成一个集群,还是建立成主备两个集群,都无法在只利用 CockroachDB 的特性的条件下,应对机房级别的灾难。解答如下:
- 将两个机房建成一个集群,当其中一个机房宕机,另一个机房利用剩下的节点继续工作?
答:如果只有两个机房,势必会有一个机房含有多数节点,当该机房关停,多数节点丢失,集群会瞬间不可用。 - 每个机房各构建一个集群,其中一个集群正常使用,另一个待命,当工作的集群宕机,数据迁移到另一个机房的集群继续工作?
答:CockroachDB 的确支持跨机房迁移数据,但前提条件是整个集群是可用的,如果集群已经宕机,是无法迁移数据的。 - 每个机房各构建一个集群,其中一个集群正常使用,另一个接收相同的写入操作,在必要时切换使用?
答:理论上可以的,但 CockroachDB 原生不支持,需要使用者在业务上自行实现。但这样意味着无论是采用 CockroachDB 还是 MySQL 其实都一样,所以这不在讨论范围内。
综上,想让 CockroachDB 集群应对什么级别(机器、机架、机房、地域、国家?)的故障,就需要 CockroachDB 集群在该级别上拥有至少 3 个跨区备份。
下面正式讨论 CockroachDB 的灾备方案。
对于 CockroachDB 而言,会引起数据不可用的“灾难”就是同时有多个节点掉线,而某个 range 的大多数 replica 又恰好都在这些节点上,这样一来,这个缺少足够 replica 的 range 将进入不可用状态。根据这一点,可见 CockroachDB 在 CAP 原理中是实现了 CP,即保证一致性和分区容错性,而放弃可用性。
需要说明的是,某些 range 不可用,不会造成其他 range 的不可用。只要读写操作的目标数据不在这些不可用 range 上,操纵仍可正常进行。
综上,可以明确以下几点:
- 某个 range 失去了大多数 replica 后,该 range 不可用;
- 需要尽量避免“生死存亡有一定相关性的节点”(比如位于同一机架或同一机房的节点)包含相同 range 的 replica;
- 由于某个 range 失去可用性后,不会影响其它 range,所以为了节省部署成本,在灾难发生时可以只保住那些重要的数据,而放弃无关紧要的数据的可用性。
基于以上共识,为了应对灾难,可以采用以下措施:
- 提高 range 的 replica 数量,降低失去多数 replica 的概率;
- 指定节点 Locality,降低含有相同 range replica 的节点同时宕机的概率;
- 定制不同的 Replication Zone,让重要程度不同的数据拥有不同的备份方案。
这三项措施是相辅相成的,在具体操作时需要综合起来考虑。下面分别进行讨论。
(1)提高 range 的 replica 数量
由于默认 range 的 replica 数为 3,这意味着,只要运气足够差,仅需同时丢失两个节点就可以造成部分数据不可用。所以提升 range 的 replica 数在一定程度上可以提高数据的可用性,但这一定是在节点足够多、足够分散的前提下。
举例来说,如果一共就只用 3 个节点,即使将 range 的 replica 数量设得再多,也不会任何帮助,反而占用磁盘空间。
反过来说,如果我有三个地域,每个地域三个机房,每个机房三个节点,在不考虑跨区复制的延迟的情况下,设置 range 的 replica 数为 3 反而是最经济且有效的方案。
(2)指定节点 locality
每个节点在启动时可以指定该节点的“位置”,即 --locality 参数,详见 https://www.cockroachlabs.com/docs/stable/start-a-node.html#locality。
该参数的指定没有固定套路,可根据实际使用自有发挥,但同一个集群的所有节点需要使用同一个套路,例如:
套路示例1:
--locality=国家=中国,机房=阿里云华东2
--locality=国家=美国,机房=阿里云美西1
套路示例3:
--locality=城市=上海,机房=浦东,机架=A
--locality=城市=上海,机房=浦西,机架=C
套路示例4:
--locality=次元=3,区域=银河系,位置=地球
--locality=次元=2,区域=神域,位置=阿斯加德
参数由多个键值对组成,如示例中的“国家=中国,机房=阿里云华东2”,事实上 CockroachDB 并不真的理解这些名字的含义,只认定越靠前的 key 所表示的范围越大,如果写成“机房=阿里云华东2,国家=中国”,CockroachDB 会认为“机房”是比“国家”更大的概念。这也要求各个节点 locality 配置的键值对顺序一定要是一致的。
有了这个参数,每个节点便可以知道自己在整个网络拓扑中的位置,整个集群可以知道整个网络拓扑的状态,便可以将同一个 range 的各个 replica 尽可能分散到不同的国家、不同的机房等。当局部网络发生整体故障,便可以在其他位置找到足够的数据备份。
除了提升集群可用性,指定 locality 还有一个好处是可以让 range lease 调整到最优的位置。举例来说,如果某个 range 有 3 个 replica,分别位于机房 A、B、C,其中 range lease 位于机房 A。但集群发现,那些连着机房 B 节点的连接总是会对该 range 进行操作,而机房 B 的节点不得不将请求转发到机房 A 的 range lease,这将大大增加操作耗时和带宽占用。所以一段时间后,集群会将 range lease 移动到机房 B,提升效率。但这样做的前提条件就是各个节点指定了 locality 信息。
(3)定制不同的 Replication Zone
Replication Zone 这个名词有点唬人,我花了很久才搞明白。直白一点说就是:同一个 Replication Zone 拥有相同的备份规则,这些规则包括 range 尺寸限制、数量、备份分布在各个 locality 上的比重等。
比如,整个集群拥有一个默认的 Replication Zone,规则是 “range 尺寸上限 64 MB、备份数目为 3、备份在各个 locality 上的分布均等”。
Replication Zone 可以应用于:
- 整个集群,即默认的 Replication Zone;
- 数据库;
- 数据表;
- 数据行(仅企业版支持)。
某个数据行的备份规则取决于按照 数据行、数据表、数据库、整个集群 的顺序找到的最先匹配的 Replication Zone 的规则。
举例来说,我有个集群分布在三个机房:A、B、C。但是我的所有业务都部署在 A 机房,且 B、C 机房的磁盘容量不高,所以我修改默认 Replication Zone 的规则:“备份数目为 3,备份只分布在机房 A”。这样,默认情况下的数据只会在机房 A 的各个节点上备份。但是,有某个数据库上的数据特别重要,万万丢不得,那么我指定一个新的 Replication Zone,规则是“备份数目为 7,分布到 A、B、C 三个机房,且在 A 机房上的分布稍微多一点(但不超过整体的 50%,否则没有意义)”。我将该 Replication Zone 应用到那个重要的数据库上,这样该数据库就会分布到 3 个机房,即使 A 机房宕机了,大多数数据不可用了,那个重要的数据库仍可用。
可见,Replication Zone 这一特性不是为了帮助提升数据可用性,而是为了帮助在提升数据可用性时,控制成本。
四、性能测试
测试用的是线上 5 台机器,每台机器 8 核 CPU,32G 内存。
但是有个问题是,驱动不能支持多个连接节点,虽然可以通过再次封装驱动来支持,但官方提供的案例是使用类似于 HAProxy 等 TCP 层的负载均衡代理,将连接分散到个节点实现压力均衡。
所以为了跳过手动封装驱动的坑,也为了方便直接使用官方提供的压测工具,我只使用了 4 台机器搭建 CockroachDB 集群,剩下的一台部署 HAProxy 和压测程序,避免各个工具之间性能互相干扰。
官方提供了多个负载生成器工具,其中 ycsb 可以做少量的写入和大量的查询,模拟多查少写的情景;rand 可以生成随机的数据进行写入,模拟只写(几乎)不查的情景。
测试过程比较粗,且个人认为测试并没有达到性能上上限,我尽可能去调优了参数,但仍不够满意,所以可能需要进一步细致的压测。
针对 1.1.7 的测试:
测试表:
CREATE TABLE usertable (
ycsb_key INT NOT NULL,
field1 STRING NULL,
field2 STRING NULL,
field3 STRING NULL,
field4 STRING NULL,
field5 STRING NULL,
field6 STRING NULL,
field7 STRING NULL,
field8 STRING NULL,
field9 STRING NULL,
field10 STRING NULL,
CONSTRAINT "primary" PRIMARY KEY (ycsb_key ASC),
FAMILY "primary" (ycsb_key, field1, field2, field3, field4, field5, field6, field7, field8, field9, field10)
)
启动参数:
/opt/cockroach/bin/cockroach start --insecure --host=$HOST --port=26256 --background --cache=20GB --http-host=$HOST --http-port=$HTTPPORT --log-dir=/opt/cockroach/log -s=/opt/cockroach/data --join=xxx.xxx.xxx.xxx:26256 --pid-file pid --max-sql-memory 10G
清空数据,重启集群。
为确保有足够多的 range 分散压力,预先向灌入 1G 左右的数据,产生了 8 个 range(为什么不是 1024 / 64 = 16 个 range?此处存疑)。
使用 ycsb 进行查询测试,并发数 2000;命令:./ycsb -duration 20m -tolerate-errors -drop=false -concurrency 2000 'postgresql://root@localhost:26257?sslmode=disable'
测试 5 分钟,测试结果:
平均每秒 8428.3 次操作,其中大多数是读,写操作约占每秒 400 次。
同时各节点系统资源占用:
- CPU 80%,内存 5.2G,带宽出 159 入 42(MBit/s)
- CPU 50%,内存 2.1G,带宽出 32 入 40(MBit/s)
- CPU 50%,内存 1.3G,带宽出 40 入 40(MBit/s)
- CPU 50%,内存 1.8G,带宽出 30 入 50(MBit/s)
使用 rand 进行写入测试,并发数 2000;命令:./rand -concurrency 2000 -method upsert -duration 5m -tolerate-errors ycsb usertable
测试 5 分钟,测试结果:
平均每秒 6285.7 次操作,全部为 upsert 操纵。
同时各节点系统资源占用:
- CPU 80%,内存 6.8G,带宽出 54 入 36(MBit/s)
- CPU 80%,内存 4.1G,带宽出 45 入 36(MBit/s)
- CPU 30%,内存 1.8G,带宽出 28 入 37(MBit/s)
- CPU 60%,内存 3.2G,带宽出 21 入 34(MBit/s)
针对 2.0.0 的测试:
测试条件一模一样,不再赘述。
查询测试,测试结果:
平均每秒 21659 次操作,其中大多数是读,写操作约占每秒 1000 次。
同时各节点系统资源占用:
- CPU 75%,内存 6.4G,带宽出 131 入 66(MBit/s)
- CPU 65%,内存 1.8G,带宽出 77 入 73(MBit/s)
- CPU 85%,内存 4.6G,带宽出 134 入 50(MBit/s)
- CPU 65%,内存 2.1G,带宽出 77 入 74(MBit/s)
写入测试,测试结果:
平均每秒 11418.1 次操作,全部为 upsert 操纵。
同时各节点系统资源占用:
- CPU 80%,内存 8.8G,带宽出 44 入 41(MBit/s)
- CPU 70%,内存 2.9G,带宽出 29 入 32(MBit/s)
- CPU 85%,内存 6.9G,带宽出 36 入 38(MBit/s)
- CPU 70%,内存 3.1G,带宽出 24 入 35(MBit/s)
可见,虽然结果不像宣称的那样性能提升 500%,但 2.0.0 相较于 1.1.7,性能上的提升还是相当可观的,提升了 2 至 3 倍。
五、兼容性问题
虽然 CockroachDB 对标 PostgreSQL 的协议,但在具体 SQL 协议上是有差异的,详见:Detailed SQL Standard Comparison。
但这些差异应该不影响我们的业务需求,所以这里讨论的是对 GUI 客户端的兼容性问题。
我尝试了用 DataGrid(支持多种 SQL 数据库)、pgAdmin4(针对 PostgreSQL)去连接 CockroachDB,均报错误,无法正常工作。
GitHub 上有个 Issue 说尝试了 DBeaver、vstudio、pgAdmin,均频繁报错,有人建议试试 Postico 但 Postico 只支持 Mac。
所以很可惜,目前为止没有找到好用的、兼容的 GUI 客户端,而 CockroachDB Admin UI 也没有提供对数据的操作。
目前社区里的讨论分为两派,一派建议强化 Admin UI,提供数据操作功能;另一派建议改善兼容性,支持主流 SQL GUI 客户端。目前官方没有明确说明倾向于走哪个方向。
至于为什么无法兼容 GUI 客户端,我个人猜测是因为数据库元数据(即“记录所有数据库所有数据表所有字段的信息”的数据表)的格式没有完全按照 PostgreSQL 设计造成的,之所以这样猜测,是因为我在性能测试过程中,发现 rand 在测 2.0.0 时无法正常工作,通过排查源码,发现是因为 rand 需要查询数据库元数据来确认目标数据表的字段信息,方便生成相应的随机数据写入。所查的表为 information_schema.columns,记录了数据库中所有字段的类型等信息。在 1.1.7 中,表示数据库名的字段为 table_schema,但是 2.0.0 改为了 table_catalog,尚不知道该修改的原因,但修改后 2.0.0 仍然不能兼容 GUI 客户端。
GUI 客户端也需要通过读取数据库元数据来确数据库、数据表结构,而 CockroachDB 的数据库元数据设计像这样说改就改,难以兼容 GUI 客户端似乎在情理之中了,
六、新版本发布
在本报告的快要完成的时候,CockroachDB 发布了 2.0.0 版本(嘴上笑嘻嘻,心里 MMP),所以本报告添加了对 2.0.0 版本的性能测试。全文其他内容除非有特别说明,否则可以认为均适用 1.1.7 和 2.0.0。
从性能测试结果可以看出,2.0.0 的性能提升相当可观。除此之外,Admin UI 也有相应的优化,更美观、更易用了,且曾加以地图形式显示节点状态的功能,如动图所示:
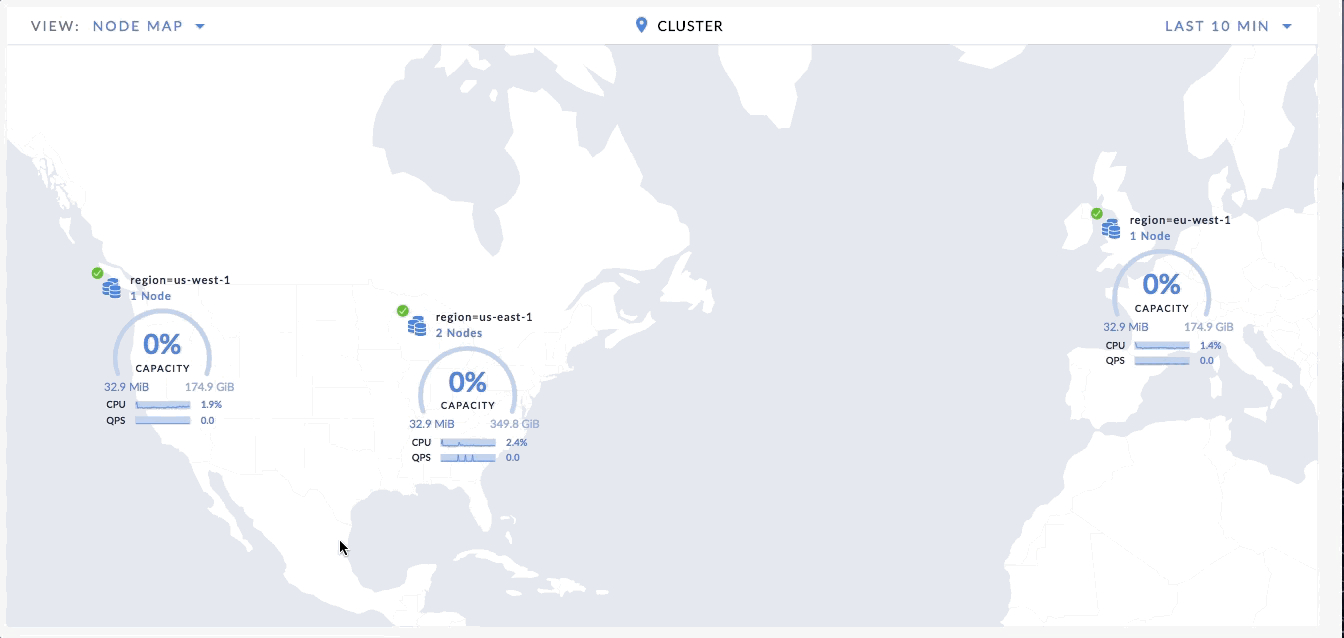
然而,该功能只向企业版用户提供……
完。
评论加载中……
若长时间无法加载,请刷新页面重试,或直接访问。