目录

本文将介绍如何搭建一个可用于生产环境的 CockroachDB 集群,目标是尽可能利用服务器资源、保证数据安全,因此搭建过程偏向繁琐,并不是一个简明的 demo 教程。如果读者只是想快速搭建一个实验环境,只需要根据官方文档介绍的如何快速搭建一个本地集群来操作即可,并不需要阅读本文,否则会把时间浪费在各种与功能无关的细节之中。此外本教程并没有采用 Docker,因为 CockroachDB 采用 golang 开发,没有环境依赖的包袱,使用 Docker 并不会使得搭建过程简化。
关于 CockroachDB 的介绍这里不做赘述,可参考:
- CockroachDB 官方文档;
- CockroachDB GitHub 仓库的 README 页;
- 我之前写的《评测分布式 SQL 数据库 CockroachDB》。
环境准备
为了演示搭建过程,我准备了如下机器:
- 192.168.100.21
- 192.168.100.22
- 192.168.100.23
- 192.168.100.24
每台机器 2 个 CPU 核心,4G 内存,20G 的磁盘,显然,这些是我用虚拟机构建的机器,仅用于演示,实际生产环境应当远远高于这个配置。机器安装了 CentOS 7 操作系统,由于 CockroachDB 并没有环境依赖,所以理论上任何 Linux 发行版均可。
事实上 CockroachDB 也支持 Windows 和 Mac,但由于官方强烈不建议在 Windows 系统上部署生产环境,而据我所知使用 Mac 系统生产环境的案例很少,所以这里默认读者是使用 Linux 作为生产环境的。
各机器之间网络通信正常,防火墙开启了 26257 端口和 8080 端口。不同发行版的 Linux 防火墙配置方式不同,读者可根据实际使用的 Linux 发行版进行操作。以 CentOS 7 为例:
firewall-cmd --zone=public --add-port=8080/tcp --permanent
firewall-cmd --zone=public --add-port=26257/tcp --permanent
firewall-cmd --reload
systemctl restart firewalld
文件准备
首先我们做个约定:我们将 CockroachDB 所有的相关文件放在 /opt/cockroach 下面,该目录下,我们准备 bin、etc、dat、log 四个文件夹,分别放置可执行文件、配置文件、数据文件、日志文件。
从官方下载页获取最新版的 CockroachDB,我得到的是 https://binaries.cockroachdb.com/cockroach-v2.0.0.linux-amd64.tgz。
登录各个机器,在每台机器上执行如下命令:
cd /opt
mkdir cockroach
cd cockroach
mkdir bin etc log dat
wget https://binaries.cockroachdb.com/cockroach-v2.0.0.linux-amd64.tgz
tar xzvf cockroach-v2.0.0.linux-amd64.tgz
mv cockroach-v2.0.0.linux-amd64/cockroach bin/
rm cockroach-v2.0.0.linux-amd64 cockroach-v2.0.0.linux-amd64.tgz -rf
此时 /opt/cockroach 的目录结构应当如下:
├── bin
│ └── cockroach
├── dat
├── etc
└── log
生成安全证书
为了开启各节点之间的安全传输,我们需要生成多个安全证书。
首先需要生成一个根证书,这个根证书所有的节点必须是一样的,所有我们需要在其中一台机器生成根证书,再拷贝到其他节点上。
在其中一台机器上,比如 192.168.100.21 上,执行如下命令:
cd /opt/cockroach/
mkdir -p etc/certs etc/my-safe-directory
bin/cockroach cert create-ca --certs-dir=etc/certs --ca-key=etc/my-safe-directory/ca.key
这时候会生成根证书的钥匙对:etc/certs/ca.crt 和 etc/my-safe-directory/ca.key。这两个文件非常重要,需要妥善保管。其中由于 ca.key 是私钥,是需要保密的,所以完成集群搭建后,需要从各个节点上删除 ca.key,避免私钥泄露。以后需要扩容添加节点时,再取出保管好的 ca.crt 和 ca.key 进行使用。
将 192.168.100.21 的 /opt/cockroach/etc/ 路径下的内容拷贝到其他节点相同的位置,各种手段均可,这里以 scp 为例:
cd /opt/cockroach/etc/
scp -r * root@192.168.100.22:/opt/cockroach/etc/
scp -r * root@192.168.100.23:/opt/cockroach/etc/
scp -r * root@192.168.100.24:/opt/cockroach/etc/
完成后,每台机器的 /opt/cockroach/ 目录下的结构应该是这样:
├── bin
│ └── cockroach
├── dat
├── etc
│ ├── certs
│ │ └── ca.crt
│ └── my-safe-directory
│ └── ca.key
└── log
接下来要用一点 shell 技巧,为了方便后续的操作,可以为每个终端会话设置一个变量,变量的值为所在机器的 IP。网上有很多“一句 shell 命令获取本机 IP”的方法,但往往不能通用,所以如果找不到用命令获取主机 IP 的方法,可以手动指定。所以我就不在这里强行炫技了,就用笨办法。
在每台机器上执行 HOST_IP="机器的IP":
# 在 192.168.100.21 上
HOST_IP="192.168.100.21"
# 在 192.168.100.22 上
HOST_IP="192.168.100.22"
# 在 192.168.100.23 上
HOST_IP="192.168.100.23"
# 在 192.168.100.24 上
HOST_IP="192.168.100.24"
完成后,开始为每个节点颁发安全证书,生成时需要指定被授予的主机的网络地址,可以是域名也可以是 IP 地址,这里使用 IP。如果某个主机尝试使用不是为其地址颁发的证书,那其他主机会不承认其合法性,拒绝与其通信。
在每台机器上执行:
cd /opt/cockroach/
bin/cockroach cert create-node ${HOST_IP} --certs-dir=etc/certs --ca-key=etc/my-safe-directory/ca.key
上述命令无需修改,可直接在各机器上运行,不同机器上因为 HOST_IP 变量值不同,生成的证书也是不同的。
成功执行后,etc/certs 下会创建 node.crt、node.key 两个文件,有了这两个文件,节点之间便可以安全通信了。
此时每台机器 /opt/cockroach 的目录结构应当如下:
├── bin
│ └── cockroach
├── dat
├── etc
│ ├── certs
│ │ ├── ca.crt
│ │ ├── node.crt
│ │ └── node.key
│ └── my-safe-directory
│ └── ca.key
└── log
启动第一个节点
首先,需要选一台机器起一个“创世节点”,该节点不是加入已有集群,而是自立门户,创建一个新集群(虽然刚开始只有它自己一个节点)。
注意,由于 CockroachDB 是完全去中心化的,节点之间完全对等,所以这个创世节点并不会因为其“元老”身份而拥有什么特殊的优待或责任。在其他节点完成启动后,创世节点即使宕机,也不会对整个集群造成什么特殊的影响。
随便选一台机器,执行如下命令……
错!我们不可以靠在终端里执行命令来启动节点,否则当节点宕机需要重启时,维护人员(可能已经不是你了)很难知道当时启动节点是执行什么命令,指定什么参数,不方便排查问题和快速重启。
所以,我们应当将启动命令写入脚本,靠执行脚本来启动节点。
随便选一台机器,比如 192.168.100.21,执行如下命令创建启动脚本:
cd /opt/cockroach/
echo '''
#!/bin/bash
set -e
HOST_IP="192.168.100.21"
/opt/cockroach/bin/cockroach start \
--background \
--host=${HOST_IP} \
--port=26257 \
--http-host=0.0.0.0 \
--http-port=8080 \
--certs-dir=/opt/cockroach/etc/certs \
--store=/opt/cockroach/dat \
--log-dir=/opt/cockroach/log \
--pid-file=/opt/cockroach/pid \
--cache=.50 \
--max-sql-memory=.25
''' > start.sh
chmod +x start.sh
各个启动参数的含义详见 Start a Node 。
这样以后我们就可以通过执行 start.sh 来启动集群了:
cd /opt/cockroach/
./start.sh
稍等几秒,看到了如下信息便说明启动成功:
CockroachDB node starting at 2018-04-14 05:48:59.784913954 +0000 UTC (took 3.5s)
build: CCL v2.0.0 @ 2018/04/03 20:56:09 (go1.10)
admin: https://0.0.0.0:8080
sql: postgresql://root@192.168.100.21:26257?sslmode=verify-full&sslrootcert=%2Fopt%2Fcockroach%2Fetc%2Fcerts%2Fca.crt
logs: /opt/cockroach/log
temp dir: /opt/cockroach/dat/cockroach-temp482110937
external I/O path: /opt/cockroach/dat/extern
store[0]: path=/opt/cockroach/dat
status: initialized new cluster
clusterID: 3730a81d-2dec-4ef1-92c9-b2a6f636b0b4
nodeID: 1
这个是否可以用浏览器访问 192.168.100.21 的 8080 端口,应当看到如下界面:
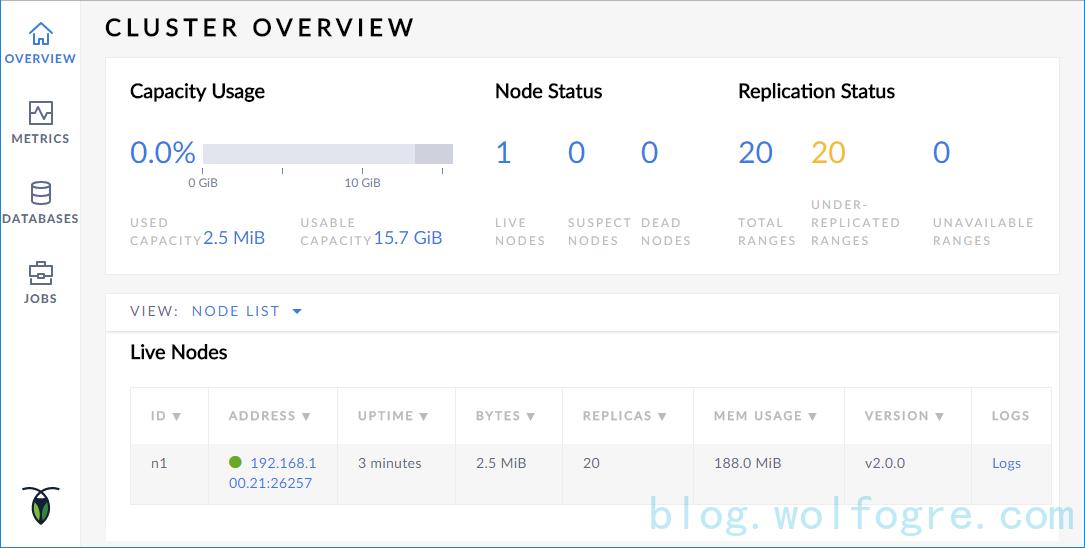
注意,由于使用了自签发证书,浏览器可能报“您的连接不是私密连接”的警告,直接忽略即可。
启动其他节点
继续启动其他节点,启动命令几乎一样,只有两处不同,一是 HOST_IP 变量需要改为所在机器的 IP,二是启动参数添加一条 --join,让新起的节点加入已有集群而不是自立门户。
在其他机器上执行如下命令创建启动脚本,注意修改HOST_IP="机器的 IP":
cd /opt/cockroach/
echo '''
#!/bin/bash
set -e
HOST_IP="机器的 IP"
/opt/cockroach/bin/cockroach start \
--background \
--host=${HOST_IP} \
--port=26257 \
--http-host=0.0.0.0 \
--http-port=8080 \
--certs-dir=/opt/cockroach/etc/certs \
--store=/opt/cockroach/dat \
--log-dir=/opt/cockroach/log \
--pid-file=/opt/cockroach/pid \
--cache=.50 \
--max-sql-memory=.25 \
--join=192.168.100.21:26257
''' > start.sh
chmod +x start.sh
这里有一个问题:--join 参数只指定了一个 IP,那么如果该 IP 所指的机器挂了,其他节点岂不是不能 join 了?解释一下,该参数指定的 IP 只是在新节点加入时充当一个“引路人”的角色,一旦新节点成功加入集群,将会获悉集群中所有节点的地址,并存入本地,至此,--join 参数的使命也都完成了,“引路人”也成了“陌路人”,从此生死不再相关。当该新节点因故宕机,再次启动时,会从保存的数据中读取其他节点信息,重新加入集群,并不会受 --join 参数影响,即使不写 --join 参数,节点也可以正确加入集群,而不是成为创世节点(除非清空该节点的数据,位于 dat 下)。那如果“引路人”宕机或者退役了,又需要加入新节点时怎么办,好办哇,集群中所有活着的节点就可以是“引路人”,随便指定一台不就得了。
在其他机器上执行 start.sh 启动节点,完成后访问任意一台机器的 8080 端口,应当看到如下界面:
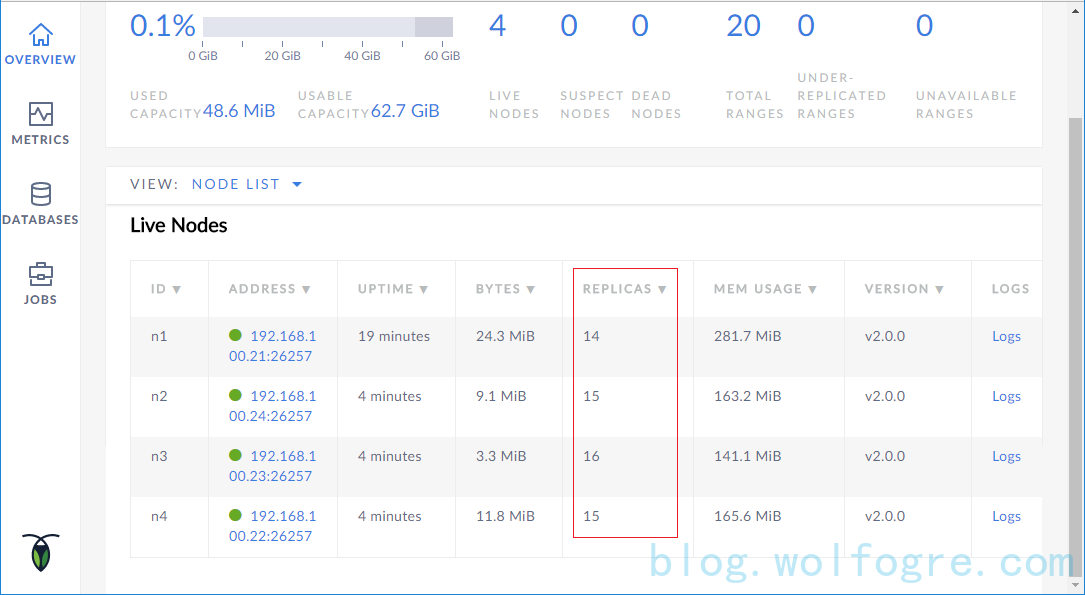
确认所有节点都已经正常加入集群,且能正常工作。一个重要的评判标准是看每个节点是否都拥有了一定量的数据备份,见图中红框标记部分。如果发现有些节点的数据备份数为 0,说明该节点与其他节点的同步操作是有问题的,可以通过排查该节点 /opt/cockroach/log 路径下的日志文件来确认问题。
此时每台机器 /opt/cockroach 的目录结构应当如下:
├── bin
│ └── cockroach
├── dat
│ ├── 000003.log
│ ├── auxiliary
│ ├── cockroach.advertise-addr
│ ├── COCKROACHDB_VERSION
│ ├── cockroach.http-addr
│ ├── cockroach.listen-addr
│ ├── cockroach-temp155584461
│ │ ├── 000003.log
│ │ ├── auxiliary
│ │ ├── COCKROACHDB_VERSION
│ │ ├── CURRENT
│ │ ├── IDENTITY
│ │ ├── LOCK
│ │ ├── MANIFEST-000001
│ │ ├── OPTIONS-000005
│ │ └── TEMP_DIR.LOCK
│ ├── CURRENT
│ ├── IDENTITY
│ ├── LOCK
│ ├── MANIFEST-000001
│ ├── OPTIONS-000005
│ └── temp-dirs-record.txt
├── etc
│ ├── certs
│ │ ├── ca.crt
│ │ ├── node.crt
│ │ └── node.key
│ └── my-safe-directory
│ └── ca.key
├── log
│ ├── cockroach.log -> cockroach.vm21.root.2018-04-14T06_32_10Z.001748.log
│ ├── cockroach.vm21.root.2018-04-14T06_32_10Z.001740.log
│ └── cockroach.vm21.root.2018-04-14T06_32_10Z.001748.log
├── pid
└── start.sh
生成客户端安全证书
为了能使用 cockroach sql 命令连接到集群进行 SQL 操作,我们需要生成客户端安全证书。这里说明一下,这里的“客户端”仅指 cockroach sql 命令。而编写代码通过驱动连接数据库,或使用适配 PostgreSQL 的终端访问数据库时,只需要提供用户名和密码即可,不需要所谓的客户端安全证书。
那为什么还要生成客户端安全证书呢?因为目前系统里只用一个 root 用户(不是 linux 的 root 用户,两者仅名字相同),而该用户是没有密码的,只能通过安全证书登录。所以如果我想新建一个可以通过用户名、密码登录的普通用户,得先通过 root 用户连接数据库来操作,这样一来为 root 用户创建安全证书就是必要的了。
不同于节点的安全证书,客户端安全证书只需要指定颁发给的用户名,与主机无关。所以只在某一台机器上创建客户端安全证书即可,并在该机器上连接数据库进行操作,无需拷贝到其他机器。且为了安全,完成所需要的操作后,应当将客户端安全证书备份到别的安全的地方,并删除节点上的客户端证书。因为这样一来,即使节点被黑客攻入,由于没有客户端证书,黑客也无法登录数据库,虽然不能阻止黑客摧毁数据,也至少能避免数据库数据泄露。
随便选一台机器,比如 192.168.100.21,执行如下命令创建客户端安全证书:
cd /opt/cockroach/
bin/cockroach cert create-client root --certs-dir=etc/certs --ca-key=etc/my-safe-directory/ca.key
完成后会在 etc/certs 下生成 client.root.crt 和 client.root.key 两个文件,我们可以将这两个文件同之前的 ca.crt 和 ca.key 一起,保存到安全的位置。
下面我们就可以在 192.168.100.21 上通过 cockroach sql 登录数据库了:
cd /opt/cockroach/
bin/cockroach sql --certs-dir=etc/certs --host 192.168.100.21 --user=root
应该看到如下内容:
# Welcome to the cockroach SQL interface.
# All statements must be terminated by a semicolon.
# To exit: CTRL + D.
#
# Server version: CockroachDB CCL v2.0.0 (x86_64-unknown-linux-gnu, built 2018/04/03 20:56:09, go1.10) (same version as client)
# Cluster ID: 3730a81d-2dec-4ef1-92c9-b2a6f636b0b4
#
# Enter \? for a brief introduction.
#
warning: no current database set. Use SET database = <dbname> to change, CREATE DATABASE to make a new database.
root@192.168.100.21:26257/>
这时候,我们创建一个数据库 database1,并创建一个用户 user1。user1 可以只通过用户名、密码来登录数据库,且权限被局限在 database1 中:
CREATE DATABASE database1;
CREATE USER user1 WITH PASSWORD 'user1_123654';
GRANT ALL ON DATABASE database1 TO user1;
可以在 SQL Statements 找到各种 SQL 语句的使用说明。
完成后输入 \q 退出会话。
备份、清理证书私钥
完成后我们需要备份 192.168.100.21 的根证书秘钥对和客户端证书秘钥对,保存在安全的地方,以后需要添加新节点或需要使用 root 用户操作时,再取出使用。
需要备份的文件列表:
- /opt/cockroach/etc/certs/client.root.crt
- /opt/cockroach/etc/certs/client.root.key
- /opt/cockroach/etc/certs/ca.crt
- /opt/cockroach/etc/my-safe-directory/ca.key
备份完成后,删除每台机器上的如下文件(如果有的话):
cd /opt/cockroach/etc/
rm -f certs/client.root.crt
rm -f certs/client.root.key
rm -rf my-safe-directory
注意,/opt/cockroach/etc/certs/ca.crt 是不需要也不可以删除的。
此时每台机器 /opt/cockroach 的目录结构应当如下:
├── bin
│ └── cockroach
├── dat
│ ├── 000003.log
│ ├── auxiliary
│ ├── cockroach.advertise-addr
│ ├── COCKROACHDB_VERSION
│ ├── cockroach.http-addr
│ ├── cockroach.listen-addr
│ ├── cockroach-temp155584461
│ │ ├── 000003.log
│ │ ├── auxiliary
│ │ ├── COCKROACHDB_VERSION
│ │ ├── CURRENT
│ │ ├── IDENTITY
│ │ ├── LOCK
│ │ ├── MANIFEST-000001
│ │ ├── OPTIONS-000005
│ │ └── TEMP_DIR.LOCK
│ ├── CURRENT
│ ├── IDENTITY
│ ├── LOCK
│ ├── MANIFEST-000001
│ ├── OPTIONS-000005
│ └── temp-dirs-record.txt
├── etc
│ └── certs
│ ├── ca.crt
│ ├── node.crt
│ └── node.key
├── log
│ ├── cockroach.log -> cockroach.vm21.root.2018-04-14T06_32_10Z.001748.log
│ ├── cockroach.vm21.root.2018-04-14T06_32_10Z.001740.log
│ └── cockroach.vm21.root.2018-04-14T06_32_10Z.001748.log
├── pid
└── start.sh
验证数据库
为验证数据库的可用性,我们使用适用于 PostgreSQL 命令行客户端连接数据库,创建一个数据表并做一些读写操作。
各个 linux 发行版的 PostgreSQL 命令行客户端安装方式可能不一样,这里仅以 CentOS 7 为例。
安装工具:
yum install postgresql
连接到数据库:
[root@vm21 cockroach]# psql -h 192.168.100.21 -p 26257 -U user1
Password for user user1:
psql (9.2.23, server 9.5.0)
WARNING: psql version 9.2, server version 9.5.
Some psql features might not work.
SSL connection (cipher: ECDHE-RSA-AES128-GCM-SHA256, bits: 128)
Type "help" for help.
user1=>
创建一个数据表并做一些读写操作:
USE database1;
CREATE TABLE usertable (id UUID PRIMARY KEY DEFAULT gen_random_uuid(), name STRING, age INT);
INSERT INTO usertable (name, age) VALUES ('a', 10), ('b', 20), ('c', 30);
SELECT * FROM usertable;
可以看到如下数据:
id | name | age
--------------------------------------+------+-----
94628e04-23f2-4bdd-83ef-d00a2a56f5fd | b | 20
c88ed9df-5ff9-468b-94bf-d9beb197136b | a | 10
eedaded5-c99a-4b8e-a7ea-52ef22a15305 | c | 30
(3 rows)
多地址连接或负载均衡
至此,一个可用与实际生产的 CockroachDB 集群事实上已经搭建完成了。但仍有一个小问题。
客户端连接集群时,只要连接某个节点,即可对全量数据进行操作。且一般的应用于 PostgreSQL 的驱动支持连接到一个地址,但问题来了,代码中应该如何确认连接哪一个节点呢?如果程序都连接到某个一个节点上,势必该节点的压力会大于其他节点,这违背了集群平摊压力的初衷。
我觉得有两个可行的方案,第一是多地址连接。代码中通过读取配置文件或读 ZooKeeper 这样的集中配置组件,来获取 CockroachDB 集群所有节点的地址,再构建一个数据库连接池,连接池中的连接均匀地连接到各个节点上,保证各个节点的压力均衡。但这个方法有一定的开发压力,可以集中实现,再暴露统一的接口,相当于对已有的 PostgreSQL 驱动做一些简单的封装,自研出一个支持多地址连接的 CockroachDB 驱动。
第二个方法是使用 TCP 层的负载均衡,使用一个地址将压力分摊到各个节点上,而客户端只需要连接负载均衡地址即可。官方文档里介绍了使用 HAProxy 做负载均衡的示例。我比较推崇这个方法,但不推崇使用自搭的 HAProxy。原因是如果该 HAProxy 所在的机器宕机了,数据库将无法连接,失去可用性,这与 CockroachDB 去中心化、防单点故障的设计理念是相违背的。如果部署多个 HAProxy,某个宕机后使用其他的呢?这就又回到了原本的问题,客户端哪知道连哪一个。
所以这里应该请专业的运维团队出场,提供一个高可用、高性能的 TCP 层负载均衡服务,据我所知,这类服务甚至不是用服务器来做的,而是有相关的专用硬件设备。这就超出了搭建 CockroachDB 的讨论范围了,故不再这里展开,也不示例如何利用 HAProxy 搭建负载均衡。
如果说公司处于初创阶段,运维团队无法提供上述的负载均衡服务,那没办法,老老实实使用多地址连接的方法吧。
最后
至此,所有工作完成,下面要做的就是验证、压测、试用、投产,并抽时间仔细阅读一下官方文档,做更深一步的了解。
祝你顺利,使用愉快~
︿( ̄︶ ̄)︿
评论加载中……
若长时间无法加载,请刷新页面重试,或直接访问。