目录
一
分享一个经历。
差不多大二的时候,我也学人家搞起了博客,那时候还没有自己搭建网站的能力,便尝试在一些博客平台上注册账户,搭建博客。最后选定在博客园上搞,这是当时认为的最佳选择。
一切准备就绪后,开始写东西,绞尽脑汁,搜肠刮肚,无奈胸中无货,没啥能写的,这就非常尴尬了。正巧那时候在尝试逼迫自己看一些英文文档,于是便想出个馊主意,在 GitHub 选一些知名项目,把它们的 README 文挡翻译成中文,贴到自己博客上。这样既能装成个技术博客的样子,还能锻炼下英语,good。
当时生怕惹什么乱子,小心翼翼在每篇开头写上:
声明:本文为笔者为练习英语所做的翻译练习,原文所属者与笔者没有任何关系,翻译结果不代表原文所属者的观点。笔者不保证翻译的正确性,任何人以任何形式的对本文的引用,都是不负责任和荒谬的行为,造成的后果笔者不予负责。
然后再小心翼翼地粘上英文原文的链接,和 GitHub 仓库的链接,生怕人家告我侵犯版权啥的。
就这样结结巴巴地翻译了几篇,博客有一点博客的样子了。
对于当时那个懵懂的骚年我来说,最开心莫过于在 Google、百度上搜索自己的博客内容,然后发现被收录了。很开心,仿佛在这嘈杂的互联网世界有了一个容自己发声的小角落。
然而有一天,我在看搜索结果时,发现个晴天霹雳。啥事呢?也就一破事儿,我现在仍然能复现当时发生的情况:
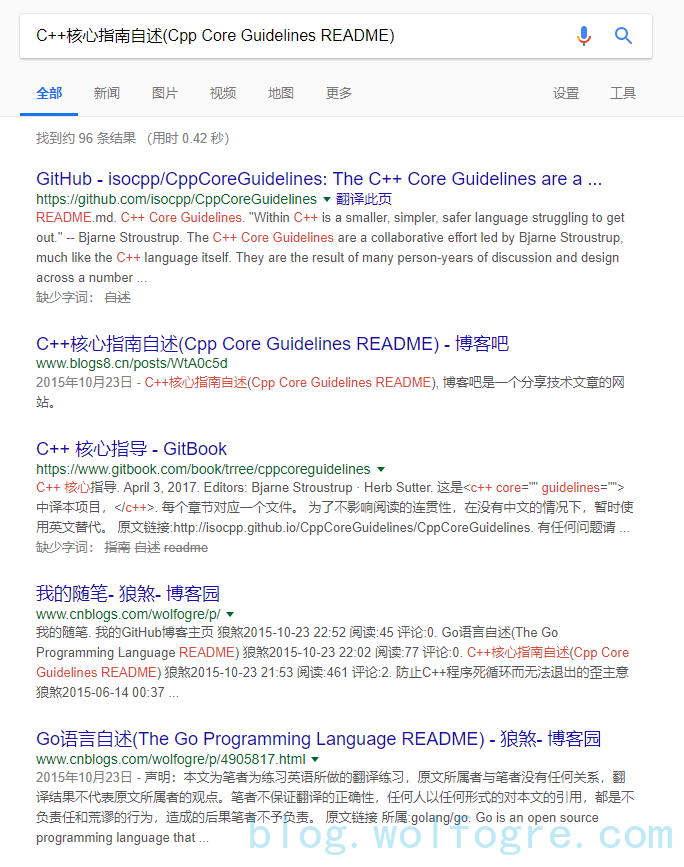
《C++核心指南自述(Cpp Core Guidelines README)》是我当时翻译 C++ 自述文档的“文章”,绝对原创,没有第二个人会干这种中二事儿了。
看搜索结果,第一条是 GitHub 的仓库,也就是英文原文的位置;我当时注册的博客排在第四、第五。这原本没啥,恶心就恶心在第二条搜索结果:博客吧,不知道什么鬼网站,点进去后内容跟我写的一模一样,而且没有转载说明或原文链接(有个“原文链接”是我加的英文原文链接)。当时我既震惊又疑惑,我这么个初出茅庐的新生写的狗屁不通的玩意儿根本没有转载价值哇。我翻看了一下博客吧的其他内容,明白了过来,这哪是什么转载,这就是靠爬虫爬取其他网站的内容来填充自己的“盗版网站”。
我写的东西,不管是干货还是垃圾,人家爬虫无脑地爬下来挂在他家网站上,搜索引擎的排名还压在我头上,而且人家这么做既没有道德约束更没有法律约束——这对我写博客的热情是毁灭性的打击。
好在这些恶心人的爬虫不是乱爬,只会挑博客园这些大肉去吃,基本上不会去搞那些不知名的小网站,尤其是自搭的博客网站。于是我放弃了博客园,也把当时写的东西全删了,走上了自搭网站做博客的路。
二
原本这事儿就过去了,当时的愤恨也化作了笑谈。直到最近我看到了个也这么干的网站,又让我想起了曾经的经历。
不打码,这个网站是 GO 语言中文网,地址是 https://studygolang.com。
因为参加工作后,技术栈主要基于 golang,经常需要搜索 golang 相关的问题,而这个网站的内容在搜索结果中往往排名很高。
不是有意去黑,我只述说几个事实:
- 该网站有一定量的原创内容和原创投稿,但绝大多是靠爬虫爬取的其他网站有关 golang 的内容;
- 该网站发布的爬虫爬取的内容,没有标明“转载”、“爬虫自动获取”、“已或原作者授权”等任何字样;
- 该网站发布的爬虫爬取的内容,最下方有标明原文链接、原作者,但我以人格担保,那是最近才有的,在此前相当长一段时间里并没有标明文章来源。
我之所以关注并知晓这些,是因为我以前翻译的 golang 自述文档也被它爬取了,现在仍被挂着,见 https://studygolang.com/articles/5067(不想给他家网站做超链接,若想访问请粘贴到地址栏)。
虽然我不再在意这些事儿了,但是我仍觉的他们的行为非常恶心。
我在这里号召所有 golang 开发者不要访问 GO 语言中文网,实在不行,点进去后再点查看原文。
是我太敏感太愤青了吗?
不,我很清醒也很冷静。
如果你质疑,且听我一一道来。
三
人家转载你写的狗屁是给你脸了,别不识相。
答:任何人都有选择识相或不识相的权利,我选择不识相。只有皇军吃馒头才可以不给钱。
转载也是人家的权利,转载有利于优秀文章的传播。
答:注意,不是“转载”,是“爬虫无脑爬的”,爬虫不会分辨文章优秀或不优秀,只会无脑地为互联网增加重复的内容,并不有利于优秀文章的传播。
人家并没有谎称文章是原创的,甚至给出了原文链接,这就没有侵犯原作者利益。
答:有没有侵犯原作者利益应当有原作者来判定,原作者有权选择不允许转载,更不允许被无脑爬取盗窃。
将某个技术领域相关的零散的文章,汇总到一个网站上,有利于用户的检索。
答:请问这个网站靠什么算法来“汇总”的?我敢在这里大放厥词:无非就是无脑地关键字匹配。但我用搜索引擎完全可以做到这一点,而且更智能,不需要这些网站自作主张来干扰来搜索引擎的算法。
可以这种网站理解为是一个门户网站。
答:门户的作用是引导流量到原链接上,而不是引导流量到一个盗版网页上。
四
综上,我对这些网站的定义是:靠无脑盗取其他网站内容来充实自己的恶心网站,它们没有为互联网增加任何实质性的新内容,反而打击原作者的创作积极性,靠杀鸡取卵的方式来完成自己的流量引入和用户积累,来获取经济上的利益。更恶心的是,这种行为在技术上无法阻止,在法律上无法追究,在道德上无法约束。
突然好绝望的说。
我唯一能做的,就是不要去访问这些恶心网站,号召大家不要去访问这些恶心网站。
但恐怕我在这磨磨唧唧小半天写了一篇狗屁,人家辛勤的爬虫早已爬了好几万了吧。
……
后记
我把发现的这类恶心网站做个列表,以后可能会不定期更新。
- 博客吧:
http://www.blogs8.cn - GO 语言中文网:
https://studygolang.com - 代码天地:
https://www.codetd.com/
评论加载中……
若长时间无法加载,请刷新页面重试,或直接访问。