目录
问题
事情是这样的,一个读写 mongo 的程序被我改出了点问题:测试同学发现,更新某类数据时,某个字段无法被修改,始终保持旧值,且程序也没有报错。
后来经过排查,问题大致是这样的,看下面这一段代码:
type Foo struct {
ID int `bson:"_id" json:"_id"`
Count int64 `bson:"count" json:"count"`
Top95Usage string `bson:"top_95_usage" json:"top_95_usage,omitempty"`
}
func main() {
foo := Foo{}
// ...
_, _ = c.UpdateOne(ctx, bson.M{"_id": foo.ID}, bson.M{
"$set": bson.M{
"top95_usage": foo.Top95Usage,
},
"$inc": bson.M{
"count": 1,
},
})
}
以上是示意代码,我已经省略了很多不必要的细节,所剩内容已经不多,区区 20 行不到的代码,我相信你如果不仔细看,仍然很难发现问题出在哪里。
注意看,定义 Foo 时,字段 Top95Usage 的 tag 是 bson:"top_95_usage",然而在构造更新操作时,写的却是 top95_usage。
这只是一个失误,写代码的时候没注意,改好就是了。但这个失误反映了一个问题,当我要利用字段的 tag 去做一些操作时,只能硬编码所关心的 tag 值。同样的情况也发生在 json 操作时:
import "github.com/tidwall/gjson"
// ...
func main() {
// ...
top95Usage := gjson.Get(string(buffer), "top_95_usage")
}
当然,只要你足够细心,或者测试用例足够完善,这个问题也没什么大不了的,难道不是吗?
那我们换个问题,如果现在需要修改字段名,将 Top95Usage 改成 TopUsage,在 golang 这样一个静态强类型语言里,做这样修改是很简单的,即使你改漏了,因为编译无法通过,你也会很快发现漏改的地方。然而,别忘了,按道理 tag 也要跟着一起改的,改为 top_usage,这时候就蛋疼了,你不知道代码里有多少地方硬编码了对 top_95_usage 的操作,如果漏改了一处,程序就要出问题了,像前面举的例子一样。
思考
既然如此,有没有办法避免硬编码呢?比如这样:
"$set": bson.M{
getTag(foo.Top95Usage): foo.Top95Usage,
},
这样的代码确实优雅多了,但很可惜,这样的 getTag 函数是实现不了的,因为 tag 信息是属于 struct,不是属于 struct 的字段的值,单纯传参 foo.Top95Usage 是无法获取到 Foo.Top95Usage 的 tag 信息的。所以你不得不这么写:
"$set": bson.M{
getTag(foo, "Top95Usage"): foo.Top95Usage,
},
实现函数 func getTag(obj interface{}, field string) string 是不难的,一通反射操作即可,但问题来了,这次我们没硬编码 top_95_usage,却硬编码了 Top95Usage,如果写错了,编译、运行也都能正常进行,又成了不容易发现的 bug:
"$set": bson.M{
getTag(foo, "Top95Usaga"): foo.Top95Usage, // 拼写错误
},
于是,我意识到要解决这个问题,思路得再打开一点。
工具
为了解决这个问题,我写了一个工具 gtag,这是一个 generator,可以帮助你生成一些代码,在解释它如何帮助你避免上述问题之前,我们先用一用看吧。
你可以通过运行 go get -u github.com/wolfogre/gtag/cmd/gtag 获取这个工具,或者在 releases 下载现成的编译结果,README.md 中有比较详细的使用介绍。
我们先用一用,解决一下前文中介绍的问题,执行命令:
$ gtag -types Foo .
generated .../main.go -> .../main_tag.go
这个命令会生成一个新文件,文件内容我们可以先不看,只需要知道它给 Foo 添加了一个新方法 Tags,使用方式如下:
tags := foo.Tags("bson")
_, _ = c.UpdateOne(ctx, bson.M{tags.ID: foo.ID}, bson.M{
"$set": bson.M{
tags.Top95Usage: foo.Top95Usage,
},
"$inc": bson.M{
tags.Count: 1,
},
})
tags = foo.Tags("json")
count = gjson.Get(string(buffer), tags.Top95Usage)
如果你担心可能会把 json、bson 都拼错,那也没关系,可以在命令中添加参数:
$ gtag -types Foo -tags bson,json .
generated .../main.go -> .../main_tag.go
然后就可以这样用了:
tags := foo.TagsBson()
_, _ = c.UpdateOne(ctx, bson.M{tags.ID: foo.ID}, bson.M{
"$set": bson.M{
tags.Top95Usage: foo.Top95Usage,
},
"$inc": bson.M{
tags.Count: 1,
},
})
tags = foo.TagsJson()
count = gjson.Get(string(buffer), tags.Top95Usage)
原理
其实只要打开生成的源文件,就能明白 gtag 做了啥了。
首先,var 中定义的一系列变量,目的是在初始化时就预先执行反射获取 Foo 的所有字段的 tag,避免在业务逻辑执行时重复反射,拖慢效率,毕竟一个结构体各字段的 tag 值是不会变的。
var (
valueOfFoo = Foo{}
typeOfFoo = reflect.TypeOf(valueOfFoo)
_ = valueOfFoo.ID
fieldOfFooID, _ = typeOfFoo.FieldByName("ID")
tagOfFooID = fieldOfFooID.Tag
_ = valueOfFoo.Count
fieldOfFooCount, _ = typeOfFoo.FieldByName("Count")
tagOfFooCount = fieldOfFooCount.Tag
_ = valueOfFoo.Top95Usage
fieldOfFooTop95Usage, _ = typeOfFoo.FieldByName("Top95Usage")
tagOfFooTop95Usage = fieldOfFooTop95Usage.Tag
)
其次,文件中定义了一个 struct 类型 FooTags,它的字段与 Foo 是一一对应的,且都是字符串类型,用于表示所对应的字段的 tag 值。
// FooTags indicate tags of type Foo
type FooTags struct {
ID string // `bson:"_id" json:"_id"`
Count string // `bson:"count" json:"count"`
Top95Usage string // `bson:"top_95_usage" json:"top_95_usage"`
}
然后是最重要的,给 Foo 附加一个 Tags 方法,返回一个 FooTags。
// Tags return specified tags of Foo
func (Foo) Tags(tag string, convert ...func(string) string) FooTags {
conv := func(in string) string { return strings.TrimSpace(strings.Split(in, ",")[0]) }
if len(convert) > 0 {
conv = convert[0]
}
if conv == nil {
conv = func(in string) string { return in }
}
return FooTags{
ID: conv(tagOfFooID.Get(tag)),
Count: conv(tagOfFooCount.Get(tag)),
Top95Usage: conv(tagOfFooTop95Usage.Get(tag)),
}
}
调用这个函数时需要指明如何提取指定 tag。必需指定 tag 名,比如 json,且可选地指定转换函数,用来转换原始的 tag 值,举例来说:
使用默认转换函数,输出
top_95_usagetags = foo.Tags("json") fmt.Println(tags.Top95Usage)传入一个和默认转换函数相同的函数,输出
top_95_usagetags = foo.Tags("json", func(in string) string { return strings.TrimSpace(strings.Split(in, ",")[0]) }) fmt.Println(tags.Top95Usage)空转换函数表示保持原样,输出
top_95_usage,omitemptytags = foo.Tags("json", nil) fmt.Println(tags.Top95Usage)自定义转换函数,输出
TOP_95_USAGE,OMITEMPTYtags = foo.Tags("json", strings.ToUpper) fmt.Println(tags.Top95Usage)
最后,TagsBson 和 TagsJson 仅是包装了 Tags("bson") 和 Tags("json"),便于调用。
考验
到这里,相信你已经清楚 gtag 的功能和原理了,那现在就要对这个工具进行一些考验,看看它能不能应对各类意外情况,保证正确运行。我们逐条来看。
- 字段的 tag 修改了,但是忘了重新执行 gtag?
这种情况其实是最不用担心的情况,因为 gtag 并不是在生成的代码里硬编码 tag 的值(虽然我有考虑过这样做),而是在执行时通过反射获取的,所以如果只是单纯的更新 tag 值,并不一定需要重新执行 gtag。
- 增加了字段,但是忘了重新执行 gtag?
如果给上文中的 Foo 追加一个字段 Enable,但没有执行 gtag,那么旧的生成代码中,FooTags 就不会有对应的 Enable 字段,如果你写 tags.Enable 就会编译错误,这个时候你就会记起来执行 gtag 了。
- 删除了字段,但是忘记了重新执行 gtag?
有注意到吗,前文中,生成的代码里有一些这样看似无意义的语句:
var (
// ...
_ = valueOfFoo.ID
// ...
_ = valueOfFoo.Count
// ...
_ = valueOfFoo.Top95Usage
// ...
)
这些语句在运行时确实没什么作用,但如果你删除了 Foo 的 Count 字段,这里就会编译失败,只有重新执行 gtag,对应的语句才会消失,而此时 FooTags 的 Count 字段也会消失,那些引用了 tags.Count 的地方就都会报错了。
- 生成的代码被误修改了?
生成的文件第一行是一句注释:
// Code generated by gtag. DO NOT EDIT.
如果写代码的人足够负责,应该会注意到这句注释并避免修改这个文件,如果他仍然尝试修改这个文件,IDE 应该会给出提示:
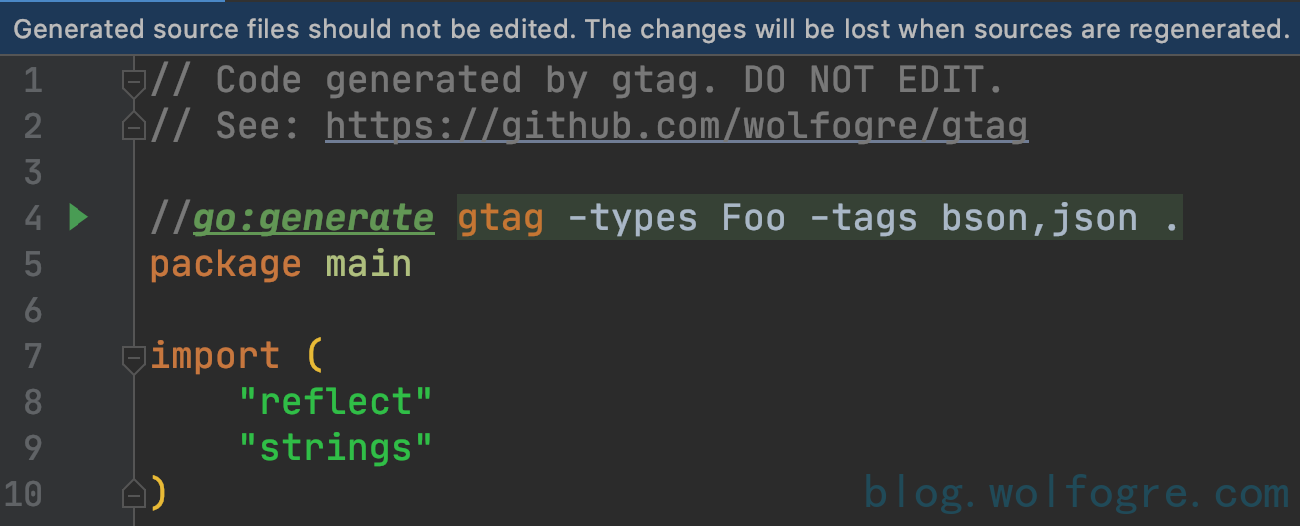
而他忽略提示仍一意孤行地去修改,那我认为他知道自己在做什么,是不会改出问题的。
最后
就不继续吹牛了,gtag 就是个小工具,能帮你解决一些问题,无它。
事实上,它是我最近沉迷于“生成代码”这件事而带来的产物,说的高大上一点就是“元编程”,说直白一点用代码生成代码,以此偷懒。golang 提供了比较完善的工具链去做这件事,有时间的话会我再写一个分享,先挖个坑。
评论加载中……
若长时间无法加载,请刷新页面重试,或直接访问。